Better Stack
Uptime monitoring, on-call scheduling, log management, and status pages bundled into one tool.
Gallery
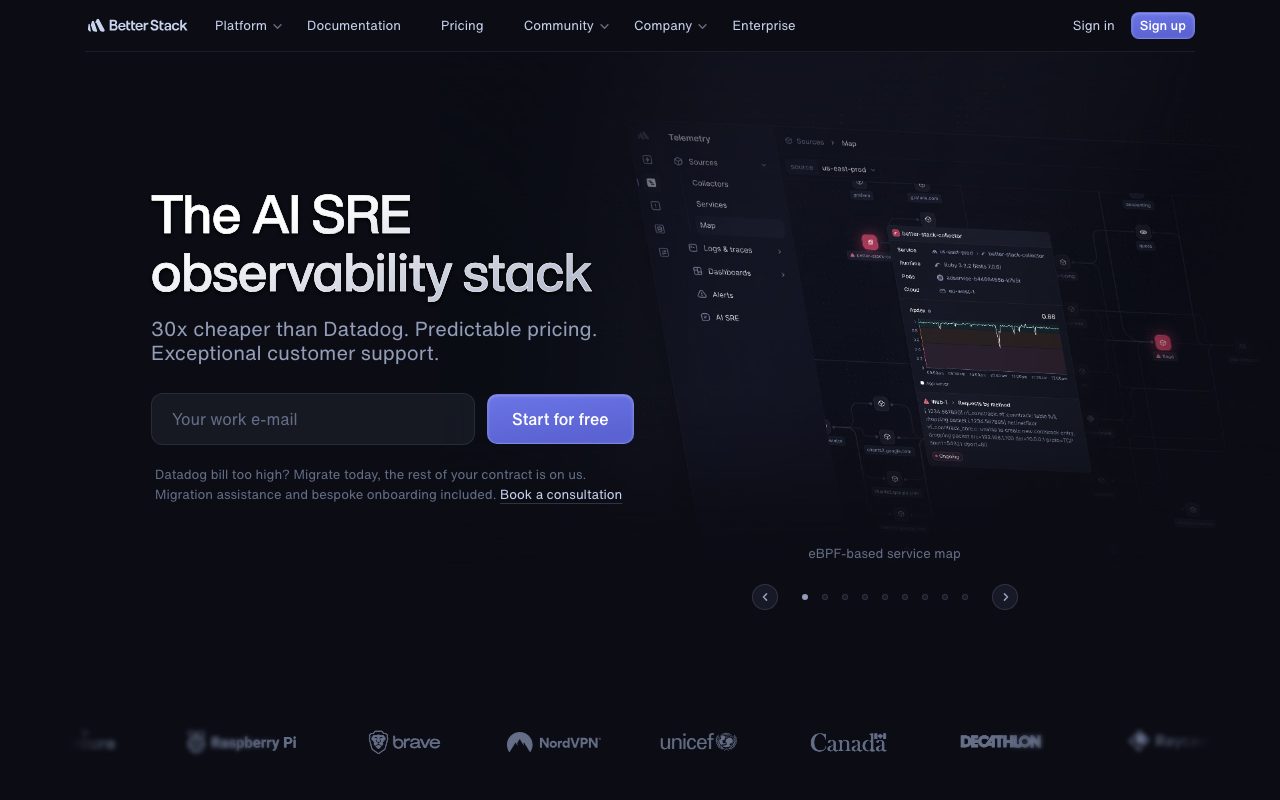
About Better Stack
Better Stack is what happens when someone looks at Datadog, PagerDuty, and Statuspage, then asks why they are three different bills. It bundles logging, uptime monitoring, incident management, and status pages under one roof. Better Stack pitches itself as the observability stack for teams that are not a Fortune 500.
The pitch is that you can stand up real monitoring in an afternoon, not a quarter. After using it on a few production apps, that holds up surprisingly well. The free tier is genuinely usable, which is rarer than vendors admit.
This is not a replacement for the deepest enterprise APM stacks. It is a replacement for the chaotic mix most small teams actually run.
What Better Stack covers
Better Stack ships four products that work together. There is Logs (formerly Logtail) for centralized logging and SQL-style queries. There is Uptime for synthetic checks, heartbeats, and on-call rotation. There is Incident.io-style incident management on top, with a status page product that customers can subscribe to.
The shared data model is the secret sauce. An alert from Uptime can pull in the logs that fired around it, page the right on-call engineer, and post the customer-facing status update from one timeline. You stop bouncing between tools to assemble a story.
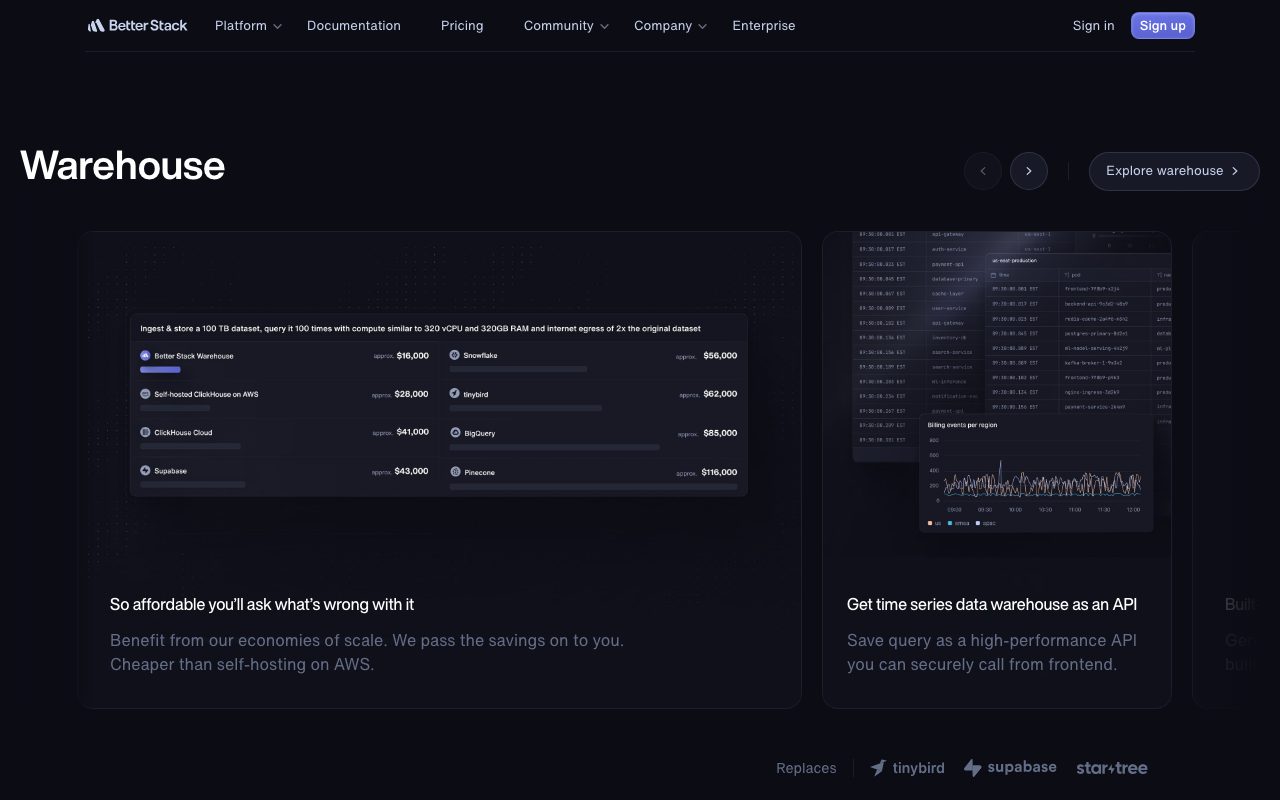
Logs are queryable in a SQL dialect, which is comfortable if you already write SQL. The query layer is fast on small to medium volumes and gets pricey on truly massive ingest. Better Stack is honest that ClickHouse-grade scale is a different conversation.
Who Better Stack is for
If you have between two and fifty engineers, Better Stack is in the sweet spot. It fits SaaS startups, indie hackers running production, agencies that host client apps, and infra teams that want one bill instead of four.
Solo founders use the free tier to wire up uptime checks and a status page in a weekend. Series A teams adopt the paid tier when they hire a second on-call rotation. Beyond that, you start evaluating the heavy hitters.
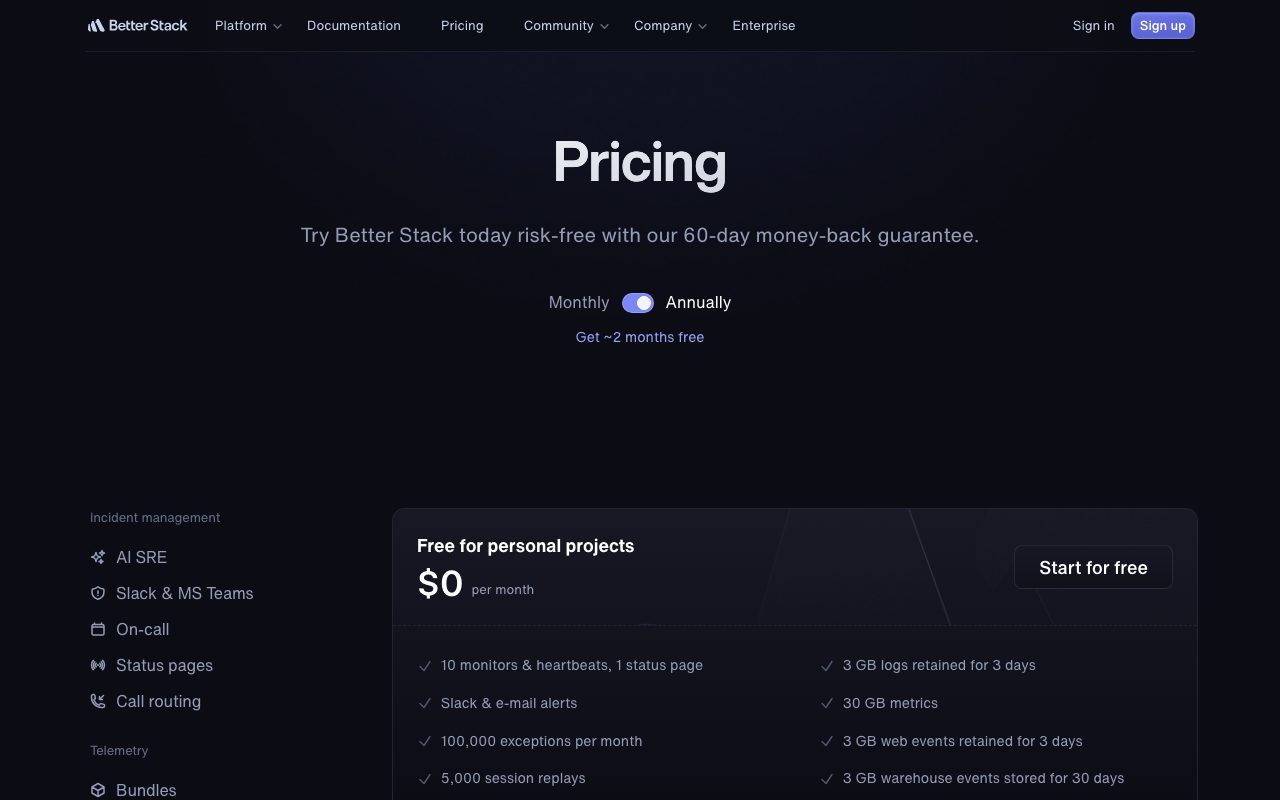
Pricing
Better Stack runs a generous free tier that covers ten uptime monitors, a public status page, basic incident routing, and a small log retention bucket. Paid plans start in the low tens per month and scale with monitors, log volume, and team seats.
The pricing is per product, so you can adopt only Logs or only Uptime if you want. Bundling all four gets a meaningful discount versus standalone subscriptions to alternatives.
Features that matter day to day
Uptime checks include HTTP, TCP, DNS, ping, SSL expiry, keyword presence, and heartbeat (cron job watch). The incident timeline is auto-built from check results, with screenshots from a real headless browser when an HTTP check fails. That screenshot has saved my evening more than once.
The status page is the cleanest one I have used. You can scope incidents to subsets of services, schedule maintenance windows, and let users subscribe by email, Slack, RSS, or webhook. Custom domains and full theming are included on paid tiers.
On-call scheduling supports rotations, escalations, overrides for vacation, and integrations with Slack, Teams, SMS, push, and phone calls. The voice call quality during an alert is, in my experience, more reliable than some bigger competitors.
Tradeoffs
The log query language is good, not great. If you live and die in complex aggregations across hundreds of GB per day, you will eventually want a dedicated tool. For most teams the included query depth is plenty.
APM and distributed tracing are not first-class yet. If you need flame graphs and span analysis, Better Stack is not the answer. Pair it with an APM tool or wait for the roadmap to catch up.
Anomaly detection on logs is rule-based, not ML-driven. Some teams will miss the auto-baseline alerts that bigger vendors offer.
Better Stack is the rare consolidation play that does not feel like a downgrade on any single axis. It just costs less and ships fewer dashboards to learn.
Better Stack vs alternatives
Versus Datadog, Better Stack is dramatically cheaper and easier to onboard, but ships less depth on traces and infra metrics. If you already pay Datadog and like it, Better Stack is not a forced upgrade. If you are evaluating fresh, Better Stack is faster to value.
Versus PagerDuty plus Statuspage plus Logtail (which Better Stack now is), the integration is the win. One bill, one timeline, one login.
Versus Grafana Cloud, Better Stack is more product-y and less DIY. Grafana wins on customization and metrics; Better Stack wins on time-to-first-alert.
See best uptime monitoring tools, Datadog alternatives, and Better Stack vs PagerDuty.
Common questions
Is Better Stack open source? No, it is a hosted SaaS. Does Better Stack support self-hosting? No, but data export is supported. Does it integrate with Slack and Teams? Yes, both, plus SMS and voice. Can it replace Statuspage.io? Yes, that is one of its core products.
Bottom line
Better Stack is a smart default for small and mid-sized engineering teams that want real monitoring without a Datadog-sized bill. The four products under one roof reduce both cost and cognitive overhead. You will outgrow it eventually if you scale to hundreds of engineers, and that is a fine problem to have.
For most teams reading this, Better Stack covers 80% of what you actually need at 20% of what you are paying. Browse tools for devops teams and the Better Stack page for live pricing.
Setting up Better Stack
Onboarding takes under an hour for the basic loop. Sign up, add your first uptime monitor (URL, expected status code, frequency), wire Slack as the notification channel. Done. The next thirty minutes is wiring heartbeat checks for any cron jobs you have.
The status page setup is similar speed. Pick a custom domain, add your services, and point your existing customers at it. Subscribers can opt in by email or RSS, which means your status page does the customer communication work for you.
Logs ingestion takes longer because you have to pick a transport. Direct application logging via a logger SDK is fastest; sending Vector or Fluent Bit configurations is more work but gives you transformation. Most teams start with the SDK and migrate later if needed.
What changes after a few months
The status page becomes the source of truth for incident communication. Customers stop emailing during outages because they can subscribe and self-serve. Your support team gets fewer "is it down" tickets. This is the unsung benefit.
The unified incident timeline becomes a habit. When something fires, the on-call engineer opens the timeline and sees the alert, the related logs, the affected services, and the customer-facing status update in one place. The mean time to context drops.
Heartbeat monitoring catches the silent failures. A cron job that should run every hour and stops running suddenly is the kind of bug that hides for days without monitoring; Better Stack catches it in the next missed window.
Migration from competitors
Coming from Pingdom or UptimeRobot, the migration is mostly a CSV import of your monitor URLs. Coming from Datadog, the logs migration is more work because the query language and dashboard structure are different. Coming from PagerDuty, the on-call schedule import is a manual setup.
The status page migration from Statuspage.io is documented and reasonable. Better Stack publishes a guide; the actual cutover usually takes a weekend.
FAQ extras
Better Stack uptime checks: HTTP, TCP, ping, DNS, SSL expiry, keyword presence, heartbeat, full browser. Each check has different cost and signal.
Heartbeat checks are unique. Your cron job pings Better Stack every run; if a ping is missed within the configured window, an incident fires. This is how you catch silent cron failures.
Status pages support component-level status. A degraded subsystem can show up without taking the whole platform down. Customer perception matters; granular status helps.
Incident postmortems can be authored in Better Stack and published. Some teams use this; others maintain postmortems in Notion or Confluence.
Better Stack offers a free tier for many features that competitors gate. The intent is to win mid-market by being good at the basic loop without enterprise pricing.
Real-world adoption pattern
A team adopts Better Stack uptime first. Within a week the on-call rotation feels lighter. The team adds the status page next; customers stop emailing during outages. The logging product follows when the team realizes their existing log tool is overpriced. Six months later, Better Stack is the central observability surface.
This is not the path every team follows. It is the most common one.
Better Stack at scale
Larger teams use Better Stack across product lines, not just one stack. Multiple workspaces with shared billing keep teams independent while consolidating procurement.
Audit logs and SSO arrive on enterprise. Most teams hit those needs around fifty engineers; smaller teams can wait.
API access lets you provision monitors, status pages, and incidents programmatically. Useful for teams that treat infrastructure as code.
The webhook receiver pattern lets external systems fire alerts into Better Stack. Combined with the timeline, it becomes the central incident surface.
Tutorial / Demo
Key Features
- Uptime checks from 14+ global regions
- On-call schedules with phone, SMS, and Slack alerts
- Log ingest with SQL-like querying
- Branded status pages with subscriber notifications
- Heartbeat checks for cron jobs and workers
Pros & Cons
What we like
- Bundle pricing beats buying four separate tools
- UI is genuinely modern
- Free tier is usable for real side projects
Room for improvement
- Log retention and volume limits hit faster than dedicated log tools
Frequently Asked Questions
Does Better Stack have a free tier?
Better Stack vs Datadog, what's the difference?
Better Stack vs PagerDuty for on-call?
Can it replace BetterUptime, Statuspage, and Logtail?
Does it handle log management at scale?
Best For
Featured in
Tags
Alternatives to Better Stack
View all
1Lookup
Real-time data verification API for phone, email, IP, and domain validation to fight fraud

BackPedal
UK bike theft protection that sends recovery agents after your stolen bike

Rollbar
Error monitoring with automated grouping and AI-assisted suggestions for which errors to actually fix first.

PostHog
All-in-one product analytics, feature flags, and session replay
Reviews (6)
Surprised how much we use this
Tried Better Stack on a side project first. Where it really wins is free tier is usable for real side projects. The log ingest with SQL-like querying is more useful than I expected. Main use case: indie devs needing real on-call without enterprise pricing. Glad I made the switch.
Pros
- UI is genuinely modern
Did exactly what I needed
Found Better Stack on a Reddit thread, glad I clicked. Where it really wins is UI is genuinely modern. On-call schedules with phone, sms, and slack alerts works the way you'd hope. Mostly using it for small SaaS teams replacing PagerDuty plus Pingdom plus Statuspage.
Pros
- UI is genuinely modern
Works, but I expected more polish
Tried Better Stack on a side project first. Where it really wins is free tier is usable for real side projects. Not perfect but better than the alternatives I tried.
Hit the Better Stack sweet spot
Honest take: Better Stack delivers most of what the marketing promises. Genuine strength: UI is genuinely modern. Worth calling out the on-call schedules with phone, SMS, and Slack alerts too.
Pros
- UI is genuinely modern
- Bundle pricing beats buying four separate tools
- Free tier is usable for real side projects
Worth the price of admission
Honest take: Better Stack delivers most of what the marketing promises. Genuine strength: UI is genuinely modern. Got real value out of heartbeat checks for cron jobs and workers. One thing that bugs me: log retention and volume limits hit faster than dedicated log tools. Worth the price for what I get out of it.
Cons
- Log retention and volume limits hit faster than dedicated log tools
Stuck the landing for our team
Tried half a dozen options before landing on Better Stack. Real selling point: UI is genuinely modern. It fits well for small SaaS teams replacing PagerDuty plus Pingdom plus Statuspage. One thing that bugs me: log retention and volume limits hit faster than dedicated log tools. Glad I made the switch.
Pros
- UI is genuinely modern
- Free tier is usable for real side projects
Badge builder
Add Better Stack to your website
Choose a badge style and size, preview it here, then copy the generated HTML. Badge images are self-contained SVGs and do not require an external script.
<a href="https://toolindex.net/tools/better-stack?ref=badge" target="_blank" rel="noopener">
<img src="https://toolindex.net/badge/better-stack/medium.svg" alt="Better Stack - Listed on Tool Index" width="180" height="50" />
</a>How to use the badge
- 1. Pick the style, size, and theme that fit your layout.
- 2. Copy the generated HTML from the code block.
- 3. Paste it into your footer, homepage, or press page.
Standard badge available
The standard listing badge is available now. Score and circle badges are limited to tools currently ranked in the top 10 of a category.
Badge clicks return visitors to this profile with a referral tag so the source remains identifiable.
Related Tools

Kevin Gabeci
Solo developer building web apps, cozy browser games, and AI creator toolkits.

Warp
The modern terminal reimagined with AI and collaboration

GitHub
Where the world builds software

Coolify
Self-hostable, open source alternative to Heroku and Netlify